Design of a simple distributed application
Introduction
Today I’m going to explain how to design a simple distributed application. The goal is to read a really big file into memory. Since the file doesn’t fit in a single machine’s memory we need to design a system to split the file across different machines. A possible architecture comprises a master that breaks the file into smaller chunks and N workers that process those chunks.
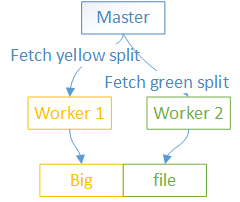
The master should implement the following:
- A way to split the work across workers. Different policies like round-robin or sending to the worker with less requests in flight are possible.
- A way of registering workers.
- A way to monitor the workers, notice if they go down and send their pending splits to other workers.
- A way to timeout if there are no workers registered or the operation takes too long.
Master and workers communicate using the following protobuf messages over a zeromq transport:
- FETCH_SPLIT_REQUEST: master -> worker. Asks the worker to fetch a split.
- FETCH_SPLIT_RESPONSE: worker -> master. The worker communicates the result of the operation to the master.
- HEARTBEAT_REQUEST: master -> worker. Send to the worker to make sure it is alive.
- HEARTBEAT_RESPONSE: worker -> master. Send response back to the master.
- REGISTRATION: worker -> master. Register worker into the master.
- SHUTDOWN: master -> worker. Used to shut down the worker.
The application works as follows. First the workers register with the master and at that point the master starts sending split requests to them. At a periodic interval the master sends heartbeats to check that the workers are still alive. If a worker doesn’t reply to a heartbeat the master removes the worker and re-sends the outstanding requests to other workers that are alive. This continues until all the splits are complete.
Master architecture
We divide the master into 2 components: master and transport.
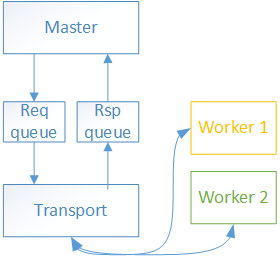
master is in charge of sending Fetch Split Requests, sending heartbeats and processing responses from workers.
transport is in charge of sending and receiving the messages.
To make the design cleaner we run master and transport in different threads and communicate them using a thread-safe producer consumer queue. Using different threads makes the application more responsive. E.g. if the master is taking a long time generating requests or processing responses the transport can still send and receive messages. This is the master’s pseudocode:
splits = splitFile(filename)
while (splits.size() > 0) {
now = get_time();
if ((now - lastSplitResponseTime) > timeoutInterval) errorAndExit();
if ((now - lastheartbeatSendTime) > heartbeatSendInterval) sendHeartbeat();
if ((now - lastHeartbeatCheckTime) > hearbeatCheckInterval) checkHeartbeats();
if (requestQueue.hasFreeSlots()) sendSplit();
if (responseQueue.hasValidData()) processResponse();
}
shutdown(workers);
Note that the queues are not blocking. This allows us to keep sending requests even if there are no responses and viceversa.
At a certain point in time the queues will look like this:
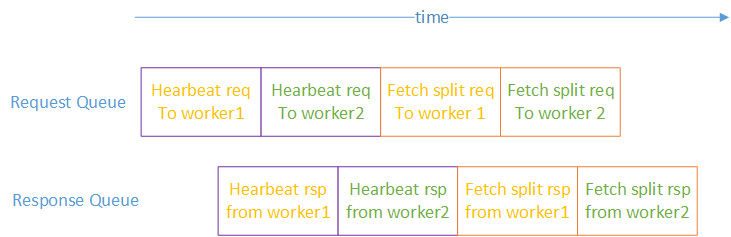
This is just a very simple design. One possible problem is that the heartbeat requests/responses may be delayed if there are too many Fetch Splits requests/responses in the queue. Another option would be to have a separate queue with higher priority for heartbeats (i.e. transport would always empty the heartbeat queue first).
Another option is to have a whole separate zeromq socket for heartbeats.
Transport architecture
The transport layer is responsible for sending and receiving messages. As in the master case is not blocking:
while (1) {
hasResponses = poll_for_responses();
if (hasResponses) responseQueue.add(response);
if (requestqueue.hasValiData()) sendToWorker(data);
}
Worker architecture
The worker is very simple. It receives requests, does the work and sends a response in a closed loop.
while (1) {
req = block_for_request();
if(req == shutdown) break;
rsp = doWork(rep);
sendToMaster(rsp);
}
The complete code is on Github in case you want to take a closer look ;).
Conclusion
When you have a big problem scaling out across a cluster of commodity machines can be a good option.
In big clusters machines fail so we need a way to check for failures and react to them.
In this example the master is not fault tolerant. We could implement a fault tolerant system using something like Logcabin or Zookeeper.